Why Optimal Scheduling Breaks User Trust
I once built a scheduling system that was provably optimal.
It was also completely unusable.
The system optimized for task ordering. It did not model the conditions that produce trust: stability, predictability, and user control. That turned out to be the wrong objective function.
The system managed a team's task queue. It ingested deadlines, priorities, and dependencies, then computed the optimal ordering across every engineer's calendar. Mathematically, it worked beautifully. In demos it looked great. Tasks slotted neatly into open windows. Deadlines were met with minimal slack. Dependencies resolved in the right order. The algorithm consistently produced schedules that no human could match by hand.
Within two weeks, every engineer on the team was pinning tasks manually. They stopped accepting suggestions. They stopped reading notifications. Eventually they stopped opening the scheduler entirely. The system still ran, but nobody trusted it.
It took me longer than I'd like to admit to understand what was wrong. The algorithm was correct; the product was broken. The problem was not recomputation itself. It was immediate, user-visible recomputation with no damping layer.
The Churn Problem
Every time a new event arrived, a dependency resolved, a meeting was added or removed, the scheduler recomputed the full schedule. Each recomputation produced a locally optimal arrangement. But from the user's perspective, their plan changed constantly.
Here is what happened to a single task over one afternoon.
Every recomputation was correct. The sequence was incoherent.
The user checked their schedule at 10 AM and planned to do the task tomorrow morning. By noon it had moved to tonight. They rearranged their evening. By 2 PM it was back to tomorrow. By 4 PM it was exactly where it started. The scheduler treated each of these as an independent optimization. The user experienced it as a system that could not make up its mind.
One complaint that stuck with me was that the scheduler had moved the same task three times during a single lunch break.
Schedule churn is not a bug in the algorithm. It is the algorithm working exactly as designed. That is the problem.
Why Humans Need Schedule Stability
Humans do not interact with schedules the way algorithms do. Algorithms optimize snapshots. Humans build plans.
An algorithm evaluates a schedule as a snapshot. A human builds a mental model of their day and makes downstream decisions based on it: when to leave for the office, what to prepare for, when to eat, what to tell their team.
When the scheduler recomputes, it invalidates that mental model. The human has to re-evaluate their plan, re-communicate with their team, and rebuild their understanding of the day. This costs real time and real cognitive effort. The scheduler does not model this cost. It treats a reschedule as a free operation. But from the user's perspective, every schedule change carries a tax. After enough changes, the user stops reading the schedule entirely.
Trust is a function of stability, explainability, and user control. Stability alone is not enough, but without it the other two don't matter. This is where optimal scheduling becomes a product failure. The system produces better arrangements than any human could, but the human cannot extract value from them because the arrangements do not stay still long enough to act on.
Modeling Stability as a Constraint
Most scheduling systems optimize a score function that looks something like this:
score = deadline_pressure + priority_weight + dependency_pressure
This captures task urgency, importance, and readiness. It does not capture stability. The fix is adding a reschedule penalty that makes the optimizer resist moving tasks that were recently placed.
def compute_schedule_score(task, proposed_slot, current_slot):
deadline_pressure = max(0, 1 - (task.deadline - proposed_slot.start).hours / 24)
priority_weight = task.priority / 10
dependency_pressure = 1.0 if all_dependencies_complete(task) else 0.0
# The term many planning tools leave out
reschedule_penalty = 0.0
if current_slot and current_slot != proposed_slot:
hours_since_last_move = (now() - task.last_rescheduled_at).total_seconds() / 3600
reschedule_penalty = STABILITY_WEIGHT * (1.0 / max(hours_since_last_move, 0.1))
return deadline_pressure + priority_weight + dependency_pressure - reschedule_penalty
This is a simplified illustration of the missing term, not a production scheduling model. In practice, the score applies across the full schedule and task interactions compound the complexity.
The reschedule penalty decays over time. A task that has been in its current slot for 8 hours has a near-zero penalty, so the scheduler can move it freely. A task that was placed 20 minutes ago has a high penalty, so the scheduler resists moving it unless the improvement is substantial.
Why inverse decay instead of exponential? Inverse creates a steep penalty for very recent moves that relaxes quickly. Exponential would create a longer tail of resistance. In practice, the sharp initial penalty matters most because the first hour after placement is when trust forms. The specific decay function matters less than having any penalty at all.
This is not a new idea. Control systems use rate-of-change penalties. Portfolio optimization includes transaction costs. Network routing uses hysteresis and dampening. The principle is well understood in those fields. It is surprisingly absent from many task scheduling products.
Task importance can be layered on top. High-priority tasks with tight deadlines get a lower stability weight because the cost of suboptimality is higher. A critical deadline should override stability. A "nice to do today" task should not move at all unless the improvement is dramatic.
The STABILITY_WEIGHT parameter controls the global tradeoff between optimality and stability. A high weight means the scheduler strongly resists churn. A low weight means it prioritizes finding the best arrangement regardless of how recently tasks moved.
When humans are in the loop, stability is not a tradeoff against optimality. It is part of optimality. A system that ignores the cost of change has an incomplete objective function.
This feels wrong to engineers. We are trained to find the best solution.
In scheduling, the best solution is often the one that stays still.
This is obvious in control systems and financial modeling. It is surprisingly rare in task scheduling products.
Engineering Patterns for Stable Scheduling
Everything starts with the stability penalty. Many planning tools do not have one, and that is the mistake. A stability-aware score is necessary but not sufficient. In production, user-visible stability also depends on when recomputations run, how changes are surfaced, and who is allowed to override whom. Four patterns work together on top of the penalty to keep the scheduler from churning.
Recomputation Windows
Instead of recomputing on every event, batch events into windows. A 15-minute recomputation cycle means the schedule changes at most four times per hour.
This is not about reducing compute cost. Modern schedulers can recompute in milliseconds. It is about reducing cognitive cost to the user. A schedule that updates every 15 minutes is a schedule the user can check, internalize, and act on before it changes again.
The window length depends on the domain. A calendar for knowledge workers might use 30-minute windows. A real-time task dispatcher for warehouse workers might use 5-minute windows. The key is that the window exists at all. Continuous recomputation is almost never the right default.
Move Thresholds
Even within a recomputation window, not every improvement is worth executing. A task that scores 0.72 in its current slot and 0.75 in a proposed slot should probably stay where it is. The 4% improvement does not justify the churn.
const MOVE_THRESHOLD = 0.15;
function shouldReschedule(
task: Task,
currentSlot: Slot,
proposedSlot: Slot
): boolean {
const currentScore = computeScore(task, currentSlot);
const proposedScore = computeScore(task, proposedSlot);
const improvement = (proposedScore - currentScore) / currentScore;
return improvement > MOVE_THRESHOLD;
}
A 15% threshold is a reasonable starting point. It means the scheduler only moves tasks when the new position is meaningfully better, not just marginally better.
The threshold can also be dynamic. Tasks that have already moved once today get a higher threshold. Tasks that have never moved get a lower one. This creates a natural damping effect: the more a task has churned, the harder it is to move again.
Freeze Horizons
Tasks within a certain time horizon are frozen. The scheduler cannot move them regardless of how much the score would improve.
A 2-hour freeze horizon means the user's immediate schedule is guaranteed stable. They can look at the next 2 hours and know it will not change. Beyond 2 hours, the scheduler can optimize freely (subject to the stability penalty and move threshold).
The freeze horizon has one exception: hard deadline violations. If a frozen task will miss its deadline because a meeting was just added to the frozen window, the scheduler must move it and notify the user explicitly. But this should be rare and treated as an escalation, not a normal recomputation.
User-Visible Stability Contracts
None of these patterns matter if the user does not know they exist.
Expose the guarantees. "Your schedule for the next 2 hours is locked." "Tasks will not move more than once per hour." "This task was pinned by you and will not be rescheduled." These are not UX polish. They are SLAs between the system and the user. Without them, the user has no way to distinguish between a stable schedule and one that happens to not have changed yet. The first builds trust. The second builds anxiety.
These patterns assume a single scheduler controlling the schedule and a single user reading it. In multi-writer systems (local-first clients, agent-driven planners, mixed-initiative tools) stability stops being an optimization constraint and becomes a consistency problem. That is its own piece.
Measuring the Tradeoff
Asserting a tradeoff exists isn't the same as measuring it. To make the claim concrete, I built stable-scheduler, a small library implementing the patterns above, and ran the same scoring pipeline across three synthetic workloads while sweeping the move threshold:
- Quiet: sparse proposals, all small toward-deadline shifts. A settled-state schedule where the optimizer rarely fires.
- Chaotic: dense proposals, mixed magnitudes. Half small marginal shifts, half larger corrective moves. A busy planning system constantly recomputing.
- Adversarial: dense proposals deliberately tuned to stay just under typical thresholds. The "many sub-threshold nudges drift the schedule under the user" failure mode.
Each curve traces fifty seeds across seven thresholds. The y-axis is mean absolute deviation of slot.end from a reference "ideal" placement of deadline - 0.5h.
The quality metric is deliberately not derived from the scheduler's own scoring function. If it were, the gate would be evaluating itself.
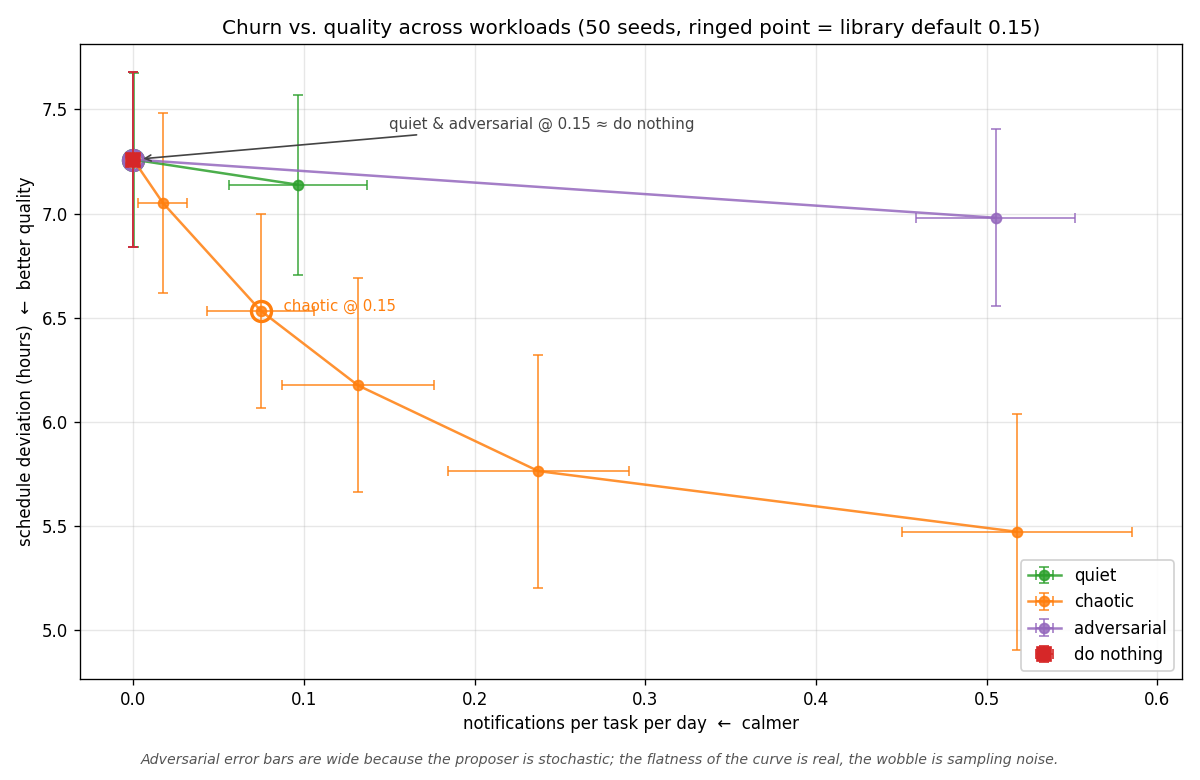
The three curves are different species, not scaled versions of each other. Churn versus quality across three synthetic workloads (quiet, chaotic, adversarial), swept across seven thresholds with 50 seeds each. The ringed point on each curve is the often-quoted default of 0.15.
The threshold mechanism works as advertised: higher threshold gives fewer notifications, monotonically, across every workload. The churn-versus-quality tradeoff is real and measurable on chaotic, where each notification "buys" roughly 3.4 hours of better placement on average. That is not a tautology. It could have been free (if all suppressed updates were noise) or catastrophic (if the scheduler depended on them). It is a moderate, roughly linear cost.
The honest takeaway is workload-dependence. The 0.15 default is defensible on chaotic, inert on quiet, and neither helps nor is meaningfully overcome by parameter tuning on adversarial. That last finding is scheduler-level, not threshold-level: adversarial is flat across the entire sweep including threshold zero, which means the proposer is producing updates the scheduler can't usefully act on. Three synthetic workloads do not span the space of real proposal streams, and one quality metric is not the only metric, but the curves are genuinely different species. There is no workload-independent right threshold, because the exchange rate between notifications and quality depends on what the proposer is doing.
Threshold-based gating produces a real, workload-dependent tradeoff between notification count and schedule quality. A single default is well-suited to chaotic proposal streams, effectively inert on sparse ones, and unable to recover quality on streams that drift under-threshold. Teams deploying this should measure their own proposal stream before accepting any default.
The Optimality-Stability Tradeoff
Stability has a real cost. A frozen schedule cannot respond to a deadline that just moved up. A high reschedule penalty means the scheduler will sometimes leave tasks in suboptimal positions. A 15% move threshold means small improvements are left on the table.
This is a deliberate engineering decision, not a compromise.
In human-facing planning systems, the sweet spot is not in the middle. It is closer to the stable end than engineers building these systems initially expect. Users will tolerate a noticeably suboptimal schedule if it is predictable. They will not tolerate an optimal schedule that changes constantly.
The goal is not the optimal schedule. The goal is the best schedule the user can actually follow.
Failure Modes of Stability
Biasing toward stability has real costs. Ignoring them is how you end up with a scheduler that is stable but wrong.
Deadline violations. A high stability penalty can cause the scheduler to miss deadlines it could have met with earlier movement. This requires an escape hatch. But every escape hatch erodes the stability guarantees the system relies on. We never found a clean solution to this. The best approach was a tiered system: soft deadlines respect stability, hard deadlines override it, and every override is logged and surfaced to the user.
Starvation of low-priority tasks. High-priority tasks with tight deadlines always win the freeze horizon exception. Lower-priority tasks that should have been rescheduled earlier get stuck in suboptimal positions because the scheduler resisted moving them. Over days, this creates a backlog of tasks in wrong slots that compounds quietly.
Local minima. A stable schedule can trap the optimizer in a local minimum. The global optimum might require moving three tasks simultaneously, but each individual move falls below the threshold. The schedule is "stable" but structurally suboptimal in ways that incremental adjustments can't fix. Periodic full recomputation (once per day, outside working hours) is one escape valve, but it reintroduces churn at a different timescale.
These are real tradeoffs, not theoretical ones. We hit every one of them. We never fully solved the tension between stability and correctness. Every system ends up with escape hatches. The question is not whether they exist, but whether they are rare enough that users still trust the system.
Scope, Assumptions, and Counterpoints
This article focuses on human-facing planning systems: calendars, task managers, and project schedulers where users build a mental model of their day and act on it.
In other domains, different tradeoffs apply. In logistics, dispatch, or trading systems, continuous recomputation is expected. In those environments, responsiveness often matters more than stability, and users are trained to operate on constantly updating information. The patterns described here would be too conservative.
The core argument is not that stability always dominates optimality. It is that when humans are in the loop, the cost of change must be part of the objective function. Systems that ignore it are optimizing an incomplete model.
The techniques in this article combine two layers:
- Objective-level stability: reschedule penalties, importance weighting, move thresholds
- System-level stability: recomputation windows, freeze horizons, authority rules, and visibility constraints
Both are required. A stability-aware scoring function alone is not enough if changes are surfaced continuously. Likewise, buffering and thresholds without modeling the cost of change leads to inconsistent behavior.
Finally, stability is only one component of trust. Explainability and user control are equally important. In many systems, the right solution is not full automation, but a mixed-initiative model where the system proposes changes and the user retains final authority.
Stability is not universally desirable. It is context-dependent. The mistake is not choosing the wrong point on the spectrum. It is failing to recognize that the spectrum exists at all.
Lessons from Production
After iterating on scheduling systems across task management and workflow orchestration:
-
The
STABILITY_WEIGHTparameter will become the most tuned constant in the entire system. You will argue about it more than any other parameter. Start conservative (high stability, low churn) and relax based on user feedback. It is far easier to make a stable system more responsive than to make a chaotic system trustworthy. -
Log every reschedule with the reason and the score delta. Without this data, tuning is guesswork. You need to answer: "Why did this task move?" and "Was the improvement worth the churn?"
-
Users who manually pin tasks are telling you the stability penalty is too low. Track pin rates as a product health metric. When pin rates climb, the scheduler is churning too much.
-
The hardest bugs are not in the scoring algorithm. They are in the interaction between recomputation timing, notification delivery, and user perception. A task that moved and moved back between two recomputation windows, where the user received both notifications, is the worst possible failure mode. The schedule is unchanged, but the user's trust is not.
-
Expose a "why did this move?" explanation for every reschedule. Users tolerate change when they understand the reason. They do not tolerate change that feels arbitrary.
We went back and added a reschedule penalty, a 2-hour freeze horizon, and a 30-minute recomputation window. The algorithm became measurably suboptimal. On paper, the schedules were worse. Pin rates fell sharply, and the team actually used it.
The deadline violation problem is still not fully solved. Neither is agent authority. But the system is usable, and that matters more than theoretical completeness.
You don't get optimality without modeling the cost of change. Many planning tools don't model it. That is the real failure.
The best scheduling system is not the one that finds the optimal arrangement.
It is the one that finds a good arrangement and leaves it alone.
References
- Local-First Software: You Own Your Data, in Spite of the Cloud· Ink & Switch
- How Figma's Multiplayer Technology Works· Figma Engineering
- Scaling the Linear Sync Engine· Linear Engineering
- Designing Data-Intensive Applications· Martin Kleppmann
- Google OR-Tools: Scheduling Optimization· Google Developers
Next
The Hard Part of AI Agents Isn't the Model →Why orchestration, retries, state, and observability matter more than prompt engineering.